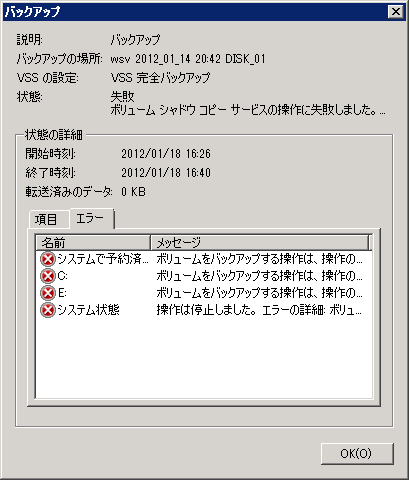
Hyper-V で子パーティションを沢山稼働させていると、Windows Server Backup が「ボリューム シャドウ コピー サービスの操作に失敗しました」と表示され、バックアップに失敗する事があります。
イベントログを見ると「volsnap 27」と「Backup 512」が記録されています。
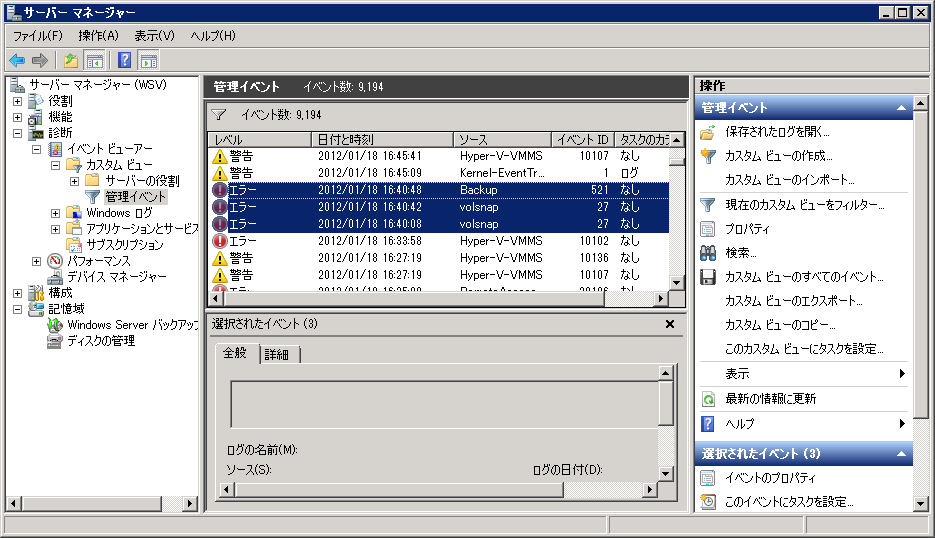
まずは、Backup 512 から見ていきましょう。
エラーメッセージには「バックアップ対象のボリュームのシャドウ コピーを作成するボリューム シャドウ コピー サービスの操作が、次のエラー コード '2155348129' により失敗したため、'YYYY - MM - DDTHH:MM:SS.mmm000000Z' に開始したバックアップ操作は失敗しました。イベントの詳細で解決策を確認し、問題の解決後にバックアップ操作を再実行してください。」とあります。
ちなみに、バックアップ開始時間の「YYYY - MM - DDTHH:MM:SS.mmm000000Z」は 世界標準時なので、日本時間に読み替えるには9時間を加えると、2012-01-18 16:26:31.3100 となるので、このログに間違いなさそうです。
エラーメッセージに「イベントの詳細で解決策を確認し」とあるので、関連のありそうな volsnap 27 を確認してみます。
すると、「重要な制御ファイルが開かなかったために、検出中にボリューム \\?\Volume {GUID} のシャドウ コピーが中止しました。」エラーになっています。
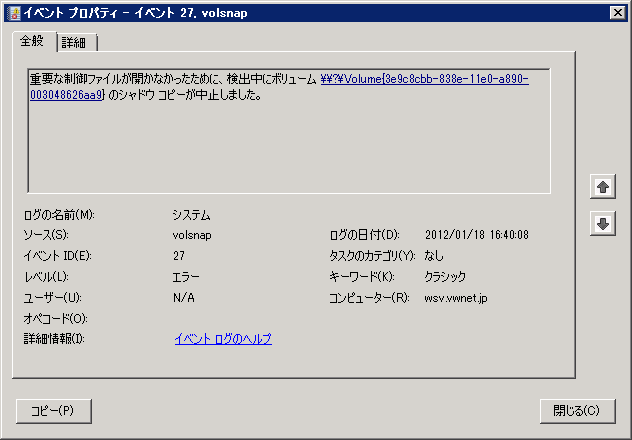
ここで悩むのが「重要な制御ファイルが開かなかったため」って何のファイルが開かなかったのか不明な点ですね。
GUID で示されているボリュームがなんなのか調べるために、mountvol コマンドでマウントポイントを確認してみます。
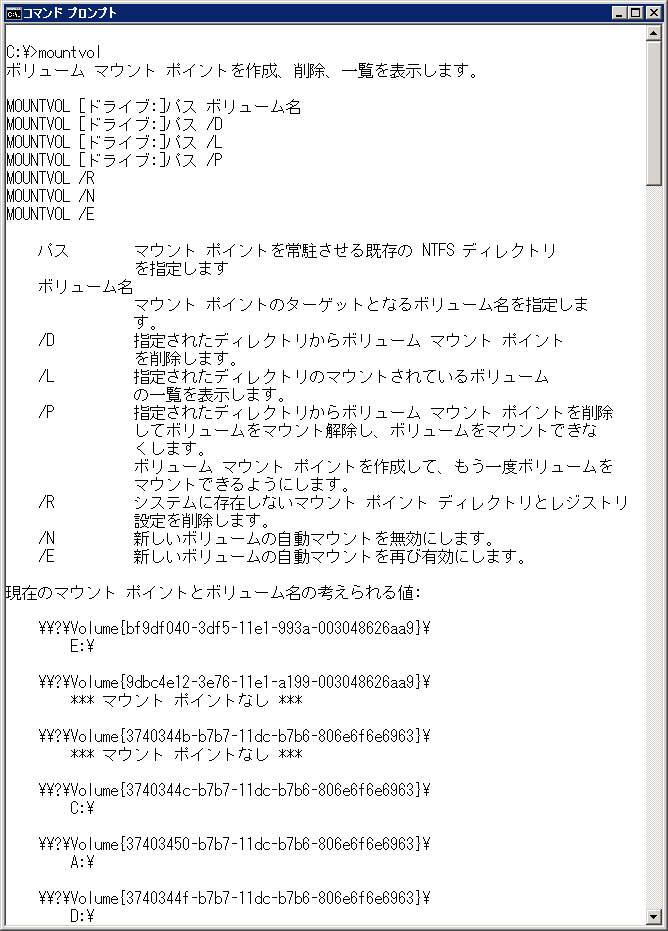
どうやら E: で volsnap 27 エラーが起きているようです。(Hyper-V の VSS Writer は、バックアップ時に動的に VHD を割り当てるような動作をするので、エラーに表示される GUID が物理ボリュームの GUID と違うので GUID のラストブロックで推測します)
このマシンの E: ドライブでは、Hyper-V の子パーティションが複数稼働しています。
ボリュームシャドウコピーが失敗する原因はいくつか考えられます。
| 1. | 不良クラスターが発生している |
| 2. | 稼働している子パーティションを Windows Server Backup するのに必要な負荷が、ディスクのキャパを越えた状態になっている |
1のケースに該当している場合は、イベントログに Disk 7 エラーが記録されているはずです。
ハードディスクは消耗品なので、Disk 7
が記録されていなくても、念のためにハードウェアチェックをしておきましょう。
サーバー専用機であれば、ハードウェア障害を確認するツールが付いているハズですので、そいつを使って確認します。
検証環境とかで自作 PC 等を使っていたりで、ハードウェア障害を確認するツールが無い場合は、SMART
対応のディスク構成なら SMART をチェックします。
ちなみに、僕が SMART をチェックする際は
Crystal Disk Info を使っています。
不良クラスターが発生している様であれば、ハードディスクを交換するのが一番良いのですが、交換するまでの間の時間稼ぎとか、しばらくだましだましで運用するのであれば、問題を起こしているディスクに chkdsk /r で修復を試みるのも良いでしょう。
余談ですが、これを書いている 2012/01 現在で chkdsk のアップデートが QFE として提供されていたりします(KB2641222)
バックアップができないので、ハードディスク交換をする前に、全子パーティションをエクスポートし、交換後にエクスポートした子パーティションを交換したディスクにコピーしてインポートします。
ハードウェア的に問題が無い場合は、稼働している子パーティションを全てシャットダウン or 保存にして Windows
Server Backup が成功するか確認します。
これでバックアップに成功するのであれば、Hyper-V VSS Writer が VSS
するために稼働している子パーティションをフラッシュしている負荷が高く、SPP(Shared Protection
Point)のスナップショット作成がタイムアウトしています。つまり、Windows Server Backup
するのに必要な負荷が、ディスクのキャパを越えた状態になっているわけです。
SAN とか高パフォーマンスストレージ環境では起きにくい現象ですが、SATA 等で環境を作っている場合はこの現象が起きやすくなります。
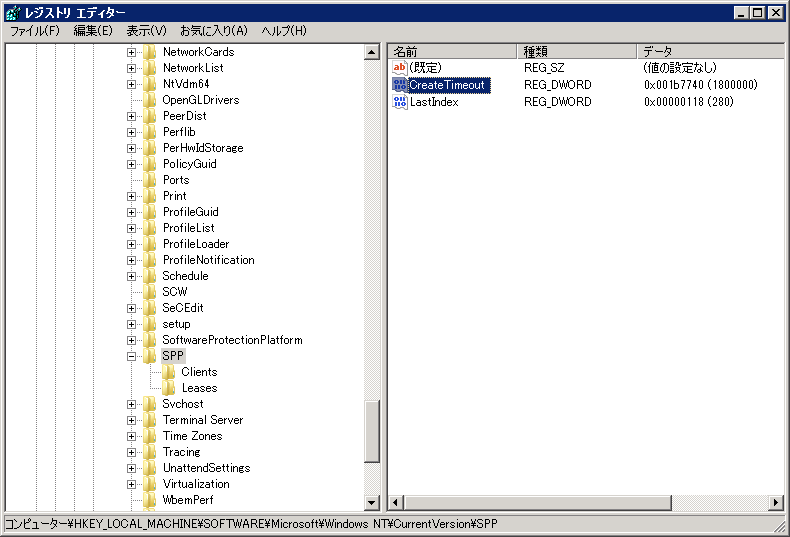
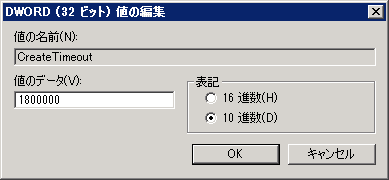
SPP のタイムアウトのデフォルトが10分(6,000,000msec)なので、子パーティション稼働のままバックアップが可能台数と稼働全台数からタイムアウト必要時間(+余裕)を求め、以下のレジストリをセットします(レジストリ編集なので、危険が伴いますし、あくまで自己責任です)
うちの環境では、6VM 稼働でバックアップが成功し、12VM 稼働環境なので、10分*2+10分の30分(1,800,000msec)に延長しました。
キー:HKEY_LOCAL_MACHINE\Software\Microsoft\Windows
NT\CurrentVersion\SPP
名前:CreateTimeout
種類:REG_DWORD
値 :タイムアウト値(msec)
レジストリをセットしたら、親パーティションを再起動すれば Windows Server Backup が成功するはずです。
これでもバックアップが失敗するようならば、MS のサポートに問い合わせしてください (^^;
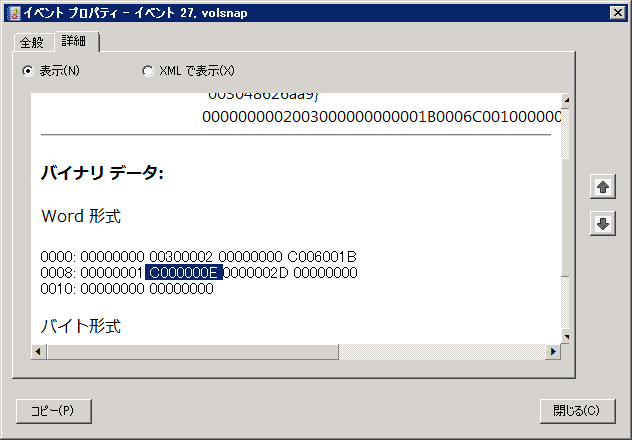
さて、ここ問題が残ってしまいました。バックアップに成功しても volsnap 27 は相変わらず出るんですよね....
更に調査をすると、今回の volsnap 27 はどうやら原因ではなかったようです。詳細を見ると「C000000E」となっており、これが意味するのは「STATUS_NO_SUCH_DEVICE」で、バックアップのために一時的に割り当てた VHD 処理が完了し VHD が切り離された後に情報を読み出しをしようとしたために発生したエラーでした。
Windows Server Backup そのものが成功していれば、このエラーは無視してかまいません。
今さらですが.... 最初に注目すべきだったのは、Backup 512 の方で、「エラー コード '2155348xxx'」が重要なキーワードでした。このエラーコードが SPP タイムアウトを表わしていたのです。
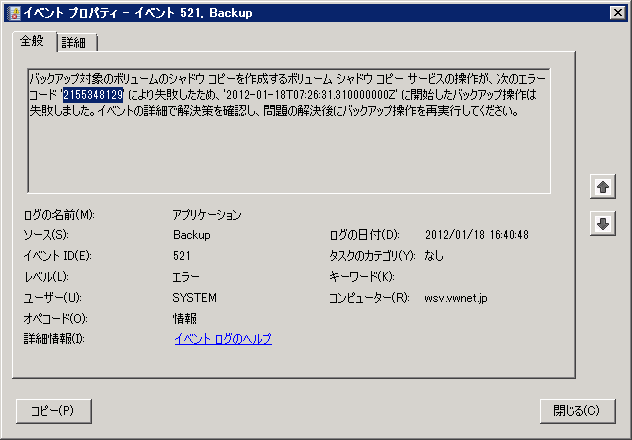
拙宅のマシンで記録されていたのは、以下の2種類でした。
2155348001
2155348129
MS サポートチームの blog である Ask CORE でもこの件が「Microsoft-Windows-Backup、ID: 521、エラー コード 2155348001 のイベントについて」として紹介されていますので、あわせてご覧ください。
![]()
![]()
Copyright © MURA All rights reserved.