翔泳社から発刊されていた DB マガジン の2010年8月号第2特集「そこが知りたいネットワーク超入門」の生原稿を元にした内容です。DB エンジニアを想定した内容なので、「IPアドレス」って言葉すら初めて聞かれる方には少し難しいかもしれませんが、トラブルシューティングを目的として来られた方は、続きのコンテンツである「はじめてのネットワークトラブルシューティング」だけを見ていただいても良いかと思います。
ネットワークと聞いて「何やら小難してよくわからない」と思われている方は意外と多いが、ネットワークとは至ってシンプルな考え方で成り立っているのだ。シンプルだからこそインターネットは全世界に普及しているし、ほぼすべての通信は IP 上に実装されている。
インターネットの中核を担っているIPも至ってシンプルな考え方で実装されている。
IP の視点からネットワーク上で何が起きているのかを見て行こう。
本題に入る前に、比喩的表現でIPネットワークの動作をイメージしておこう。
今あなたは自宅にいるとしよう。近所への買い物は徒歩なり自転車なりで直接目的地に行く事が出来る。
では、ホワイトハウスに行きたい場合どうするか?
時刻表や旅行ガイドを調べて、交通機関を決めてから移動を開始するはずだ。
ところがIPネットワークは面白い方法でホワイトハウスまで旅をするのだ。
まずはホワイトハウスの住所を調べ、最寄の駅に行って「この住所に行きたいのだが、どこで乗り換えればいいのか?」と駅員に問いかける。すると駅員は「よくわからないから、とりあえずターミナル駅になっている横浜駅まで行ってくれ」と答えた。
横浜駅に行ってまた駅員に問いかけると、今度は「知らない住所だね。とりあえず東京駅に行ってくれ」と言われた。
東京駅で聞くと「海外だね。それならば成田に行ってくれ」と言われ、成田では「JFK空港に行け」と言われ、JFK空港では...
![]()
こんな感じで、乗換の都度次の乗り換えを聞いて目的までたどり着くのが IP ネットワークだ。
なんだかひどく行き当たりばったりのような感じがするが、実はこの行き当たりばったりが大切な意味を持っている。
さて、ここからが本題だ。IP アドレス設定をした事はあるだろうか? 「IP アドレス」「サブネットマスク」「デフォルトゲートウェイ」とのアレだ。
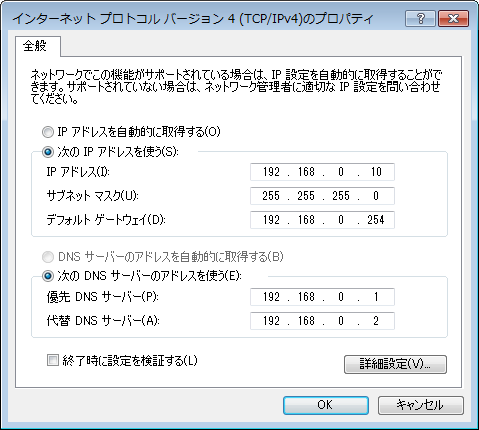
IP は、「IP アドレス」「サブネットマスク」「デフォルトゲートウェイの3つさえ設定してあれば、隣にあるコンピュータであっても地球の裏にあるコンピュータであっても通信する事が出る。実に不思議な事だが、これもシンプルな仕組みで実現されているのだ。
192.168.0.10のような IP アドレスには「ネットワーク ID」と「ホスト ID」の2つの意味が隠されている。ネットワーク ID とホスト ID を分離するが255.255.255.0のように設定する「サブネットマスク」だ。
サブネットマスクは、ホスト ID を表すビットマスクだ。IP アドレスにサブネットマスクを AND 演算して求められるのがネットワーク ID で、残りがホスト ID となる。
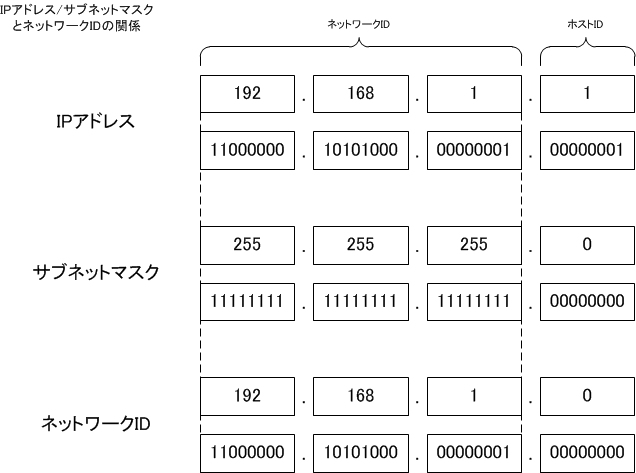 |
この「ネットワーク ID」は、ネットワークの単位を表しており、ネットワーク ID が等しいコンピュータは同じネットワーク上に存在しているので直接通信ができることを意味している。つまり「近所」と言う事になる。
サブネットマスクはビットマスクなので、ビット数で表現することもある。例えば、255.255.255.0 は 24 ビットのビットマスクなので、192.168.1.1/24 と表現する。このように「/」で表現するのを CIDR (Classless
Inter-Domain Routing/サイダー)と呼んでいる。
CIDR が登場する前は、ネットワーク ID はクラス A (255.0.0.0)、クラス B (255.255.0.0)、クラス C (255.255.255.0)の3種類が基本であり、固定 IP アドレスのインターネット接続を申請すると、最小単位でもクラス C が割り当てられていた時期がある。しかし、クラス C を割り当てていると、インターネット上の IP アドレスをあっという間に使い切ってしまうので、8ビット単位ではなく1ビット単位でネットワーク ID を構成するようになった。その時に登場したのが CIDR だ。ルータなどの通信機器ではサブネットマスクではなく CIDR を使うのがスタンダードだ。
| CIDR | サブネットマスク |
| /8 | 255.0.0.0 (Class A) |
| /9 | 255.128.0.0 |
| /10 | 255.192.0.0 |
| /11 | 255.224.0.0 |
| /12 | 255.240.0.0 |
| /13 | 255.248.0.0 |
| /14 | 255.252.0.0 |
| /15 | 255.254.0.0 |
| /16 | 255.255.0.0 (Class B) |
| /17 | 255.255.128.0 |
| /18 | 255.255.192.0 |
| /19 | 255.255.224.0 |
| /20 | 255.255.240.0 |
| /21 | 255.255.248.0 |
| /22 | 255.255.252.0 |
| /23 | 255.255.254.0 |
| /24 | 255.255.255.0 (Class C) |
| /25 | 255.255.255.128 |
| /26 | 255.255.255.192 |
| /27 | 255.255.255.224 |
| /28 | 255.255.255.240 |
| /29 | 255.255.255.248 |
| /30 | 255.255.255.252 |
| /31 | 255.255.255.254 |
| /32 | 255.255.255.255 |
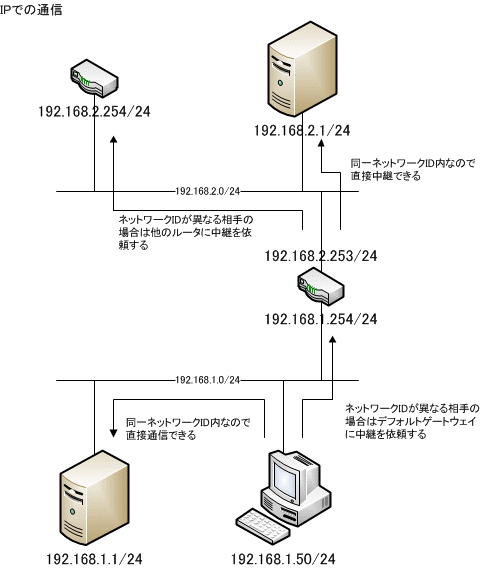
直接通信ができるコンピュータと通信する場合はそのまま通信を開始すれば良いが、直接通信ができない(異なったネットワーク ID を持ったコンピュータ)と通信する時にはどうすればいいのであろうか?
ここで「デフォルトゲートウェイ」の出番だ。デフォルトゲートウェイは、ネットワークの出口の IP アドレスで、先の比喩では「最寄駅」となる。
デフォルトゲートウェイにルータの IP アドレスを設定し、直接通信できない相手に対する通信はLANの出入り口であるルータに中継依頼をするのである。
送信元のコンピュータは、ルータに中継を依頼した後は目的のコンピュータに届くか否かは関知しない。あとはルータ任せだ。
ルータは2つ以上の通信ポートを持っており、コンピュータと同様に直接通信できるか相手かそうでないかを判断している。
ルータが直接通信できるコンピュータ宛の通信であれば、受け取ったパケットを目的のコンピュータに渡すのだが、直接通信ができない相手の場合は別のルータに再度中継を依頼する。比喩に出てきた「駅員の回答」だ。
インターネットは、このバケツリレーの繰り返しで地球の裏とも通信が出来ているのである。
 |
実際のインターネットは一本道ではなく、数多くの ISP (インターネットサービスプロバイダ)が網の目のように相互接続されており、ISP 内のネットワークもルータが網の目のように配置されるている。企業内のネットワークも同様に網目状に構成されている事が多い。
そうすると「膨大な数のルータが配置されているインターネットで、どのルータに中継を依頼すれば目的のコンピュータに届くのかわからないとダメなんじゃないの?」という疑問が出てくる。
その疑問を解決するのが「ルーティングテーブル」だ。
ルーティングテーブルは、「この宛先はどのルータに中継を依頼すればいいのか」をコントロールしているデータベースだ。
IP ネットワークの地図ともいえるルーティングテーブルは、宛先ネットワークごとに中継を依頼するルータ(Next
hop)が指定されている。これは「次の乗り換え駅」だ。
ネットワーク上に存在するすべての宛先ネットワークをルーティングテーブルに登録するのは効率が悪いので、コンピュータ同様に「デフォルトゲートウェイ」を設定することができる。最寄駅ではデフォルトゲートウェイしか設定されていないし、各駅で成田に向かう乗換を答えていたのは成田に向かう経路がデフォルトゲートウェイに設定されていたからだ。
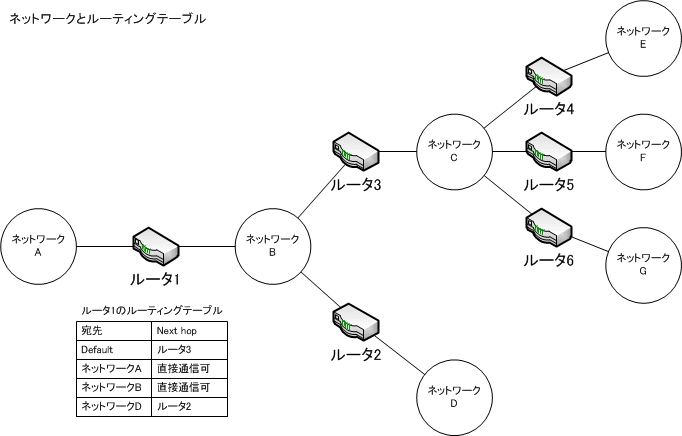 |
中継依頼を受けたルータは、直接通信できるネットワークであればそのまま中継をし、直接通信ができない宛先の場合は、自分が持っているルーティングテーブルを調べて、中継を依頼すべきルータを知ることができる。自分が知らないネットワークが宛先になっている場合はデフォルトゲートウェイに中継を依頼するのだ。
ルータは、送信元のコンピュータと同様に、自分と通信できるルータの存在しか知らず、その先に出どのような中継をされるのかについては一切知らない。
デフォルトゲートウェイが設定できるといっても、インターネットのような巨大なネットワークの場合、ルーティングテーブルを手動で設定するのは非現実的だし、巨大なネットワークではどこかしらで故障してして通信できなくなることも良くある話だ。
このような手動管理が難しいネットワークでは、RIP や OSPF 等のダイナミックルーティングと呼ばれるルーティングテーブルの自動学習プロトコルを使ってルーティングテーブルを自動管理している。
ダイナミックルーティングでルーティングテーブルを構成していれば、途中通信できない区間が出ても、動的に経路を変更して目的地に到達することが出来る。
成田エクスプレスが不通になっていた場合、東京駅では上野駅に行くように回答を変更し、上野駅では京成成田に行くように回答すればいい。最初から経路を決めていては不通になった時に対処が出来ないが、都度ルーティング先を判断していれば、生きている経路に迂回して目的地に到達することが出来るのだ。
このようにシンプルで局所的な管理の積み重ねで、世界最大のIPネットワークであるインターネットであってもネットワーク全体が機能するになっている。
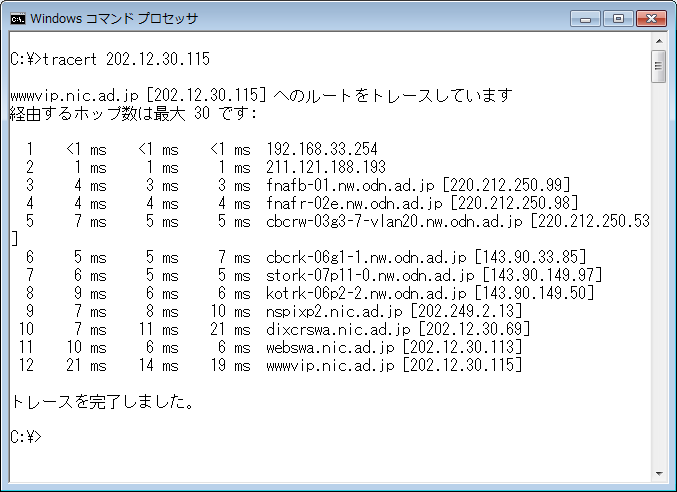
実際にどのように中継されているかを確認するコマンドが traceroute(Windows では tracert)コマンドだ。
インターネットに接続されているのであれば、試しに 202.12.30.115(www.nic.ad.jp)に対して traceroute
をしてみると、どのように中継されているのかがよくわかる。
IP 通信が地球の裏側まで到達できるのはご理解いただけたと思う。しかし、我々がIPネットワークを使う際にIPアドレスを直接入力するケースは稀だ。例えば、Web ブラウザで Web サイトをアクセスする時には、http://www.shoeisha.co.jp/のように、名前(FQDN)を使ったアクセスをしている方が圧倒的に多い。
IP ネットワークの場合、通信相手は IP アドレスで指定するので、何らかの方法で名前からIPアドレスに変換する必要がある。先の比喩で、ホワイトハウスの住所を調べたところだ。
この名前から IP アドレスに変換することを「名前解決」と呼んである。
一番原始的な名前解決方法は、コンピュータの中に IP アドレスと名前の対比表を作って、名前解決する方法だ。
この対批表方式は、インターネットの黎明期に実際に使用されていた名前解決方法だ。
この対比表は「hosts」と呼ばれるファイルで、今でも現役仕様として使用されている。
ちなみに、Windows
7では"C:\Windows\System32\drivers\etc\hosts"が存在しており、このファイルに IP アドレスと名前を記述すれば名前解決データを追加することができるようになっている。
hosts で名前解決をしていた当時は、インターネットに接続されているコンピュータの数も少なく、ネットワークに新しいコンピュータが接続された場合は、対比表を更新(あるいは配布)すれば良かったが、加速度的に接続コンピュータ数が増えていくインターネットでは、この方法では破綻する日がそう遠くないであろうことは容易に想像ができる。
データベースエンジニアであれば、「そんな原始的な事をしなくても、名前解決とIPアドレスをデータベースに登録すれば良いじゃないか」と思われるであろう。この IP アドレスと名前のデータベースが「DNS」だ。
サーバに固定 IP アドレスをする際には、DNS のIPアドレスも指定しなくてはならない。ここで指定した DNS で名前解決をしているわけだ。
組織内に存在するサーバに対する通信であれば、DNS データのメンテナンスも不可能ではないが、インターネット上に存在するホストは日々膨大な数の追加/変更/削除がされている。ネットワーク管理者は日々このメンテナンスに追われているのだろうか?
それとも、レプリケーションを張っているのであろうか?
DNS は実に興味深い手法でこの問題を解決しているのだ。その答えは「www.shoeisha.co.jp」のように表現されている FQDN の構造の中に隠されている。
DNS はルートを頂点としたツリー構造になっている。
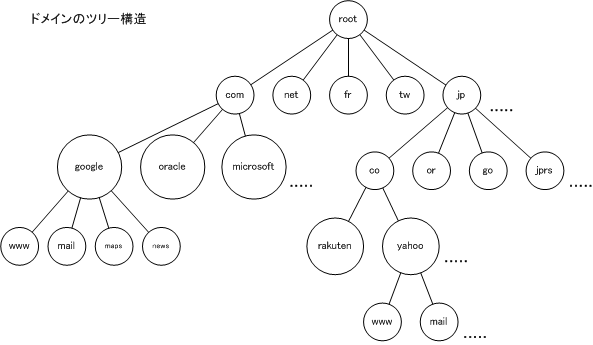 |
インターネット上の名前解決は「たらいまわし」なのだ。まず root を管理している DNS に「www.yahoo.co.jpのIPアドレスは何ですか」と問い合わせる。すると root-DNS
は「それらな jp を管理している DNS を紹介するので、そっちで聞いてくれ」と回答をする。jp を管理している DNS に同様に問い合わせると「co.jp」を管理している DNS を紹介され、co.jp を管理している DNS を管理している DNS に問い合わせるとyahoo.co.jp を管理している DNS を紹介される。
たらいまわしでたどり着いた yahoo.co.jp を管理している DNS は、www.yahoo.co.jp の IP アドレスを知っているので IP アドレスを回答してもらえるといった具合だ。
実社会でこのような対応をされると頭に来るが、DNS はこのようなたらいまわし方式なので、サーバーの IP アドレスを管理している DNS は末端の DNS だけで済んでいるし、上位の DNS は下位に存在している DNS だけを管理していれば良い事になり、ここでもシンプルで局所的な分散管理の積み上げで全体がうまく動くようになっている。
では、実際にたらいまわしされる様子を見てみよう。今回使用するツールは「dig」であるが、残念ながら Windows 系の OS には dig が標準ツールとして入っていないので、Windows で動作確認するのであれば別途 dig を入手しなくてはならない
dig for Windows
http://members.shaw.ca/nicholas.fong/dig/
dig の準備が出来たら、以下のコマンドを打ってみよう
dig @最寄りのDNS 問い合わせるFQDN +trace
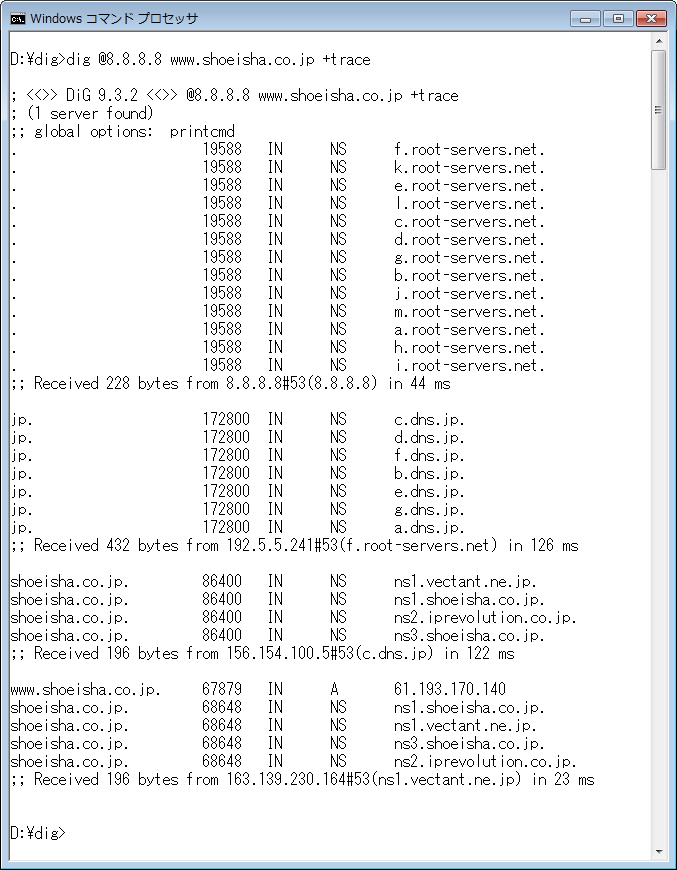
(8.8.8.8 は Google
が提供している公開キャッシュ DNS の IP アドレス)
dig の結果を見ると、まずはルート DNS が紹介され、続いて jp を管理している DNS が紹介されている様子がよくわかる。jp ドメインの場合は jp を管理している DNS が組織を管理している DNS まで管理しているので、co.jp を管理している DNS の紹介プロセスは存在しておらず、組織が管理してる DNS がターゲット FQDN の IP アドレスと、組織を管理している DNS を回答している。
ルート DNS がダウンすると、インターネットそのものが停止してしまうのでルート DNS は13存在しており、すべての DNS は同じ内容を持っている。同様の理由で各階層の DNS も複数存在しているし、組織を管理している DNS も基本的には複数で運用されている。
余談だが m.root-servers.net は日本の WIDE プロジェクトが管理をしているルート DNS だ。
実は、DNS には2つの機能が稼働している。
その1つが今まで説明してきた"たらいまわし要員"である登録されているデータのみを回答する「コンテンツサーバ」だ。コンテンツサーバはインターネット上に公開されているサーバだ。
2つ目が、クライアント PC 等からの FQDN 名前解決リクエストを受け取り、インターネット上のコンテンツサーバのたらいまわしをまわってきたり、上位のキャッシュサーバにリクエストをフォワードしてインターネット上の名前解決をする「キャッシュサーバ」である。
キャッシュサーバは組織内部に設置されるのが一般的だ。
キャッシュサーバはその名の通り、公開されている DNS 回答をキャッシュしており、キャッシュに存在していない時のみインターネット上のコンテンツサーバを検索してくる。
ルート DNS は世界で一番忙しい DNS なので、A-M の13に分散され、それぞの DNS も複数台で運用されているが、キャッシュサーバはこの負担を軽減するようになっている。
また、クライアント PC にも DNS キャッシュが存在しており、自分自身にキャッシュされている場合は、キャッシュ DNS に対して名前解決リクエストをしないようになっている。
余談であるが、近年このキャッシュ機構を攻撃するクラックする「DNS キャッシュポイゾニング」が問題になっている。
DNS キャッシュポイゾニングは、コンテンツサーバが回答する IP アドレスを詐称して偽の IP アドレスを送り込み、偽の IP アドレスをキャッシュさせるクラック手法である。例えば www.yahoo.co.jp のキャッシュに不正なサイトの IP アドレスが登録されると、キャッシュが生きている間は不正サイトに誘導されることになる。
キャッシュが汚染されにくいように DNS の設定変更すれば危険性は低減されるが、DNS の仕組み上根本的な解決が出来ないので、DNSSEC の導入が現在進んでいる。
少し話題を変えて、メールがなぜ相手に届くかを考えてみよう。
筆者のメールアドレスは mura+web@vwnet.jp
であるが、このメールアドレスを見るとドメイン名である vwnet.jp しか情報がなく、届けたいメールサーバのIPアドレスがわからない。
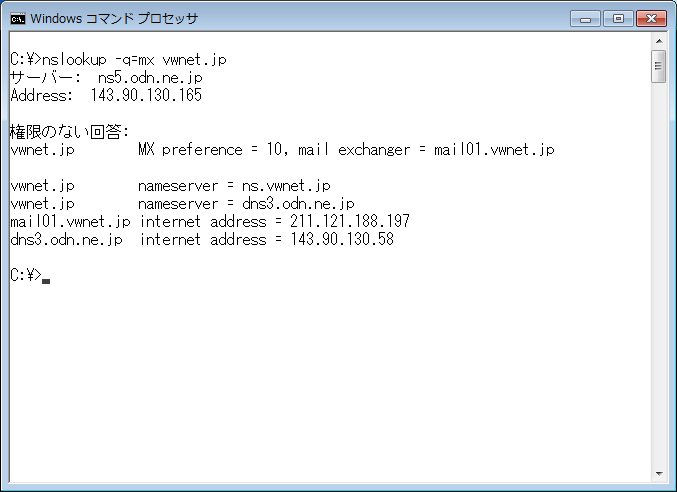
DNS 問い合わせツールである nslookup で vwnet.jp を問い合わせてもメールサーバの IP アドレスは表示されない。

実は、DNS にはリソースレコードと言う概念があって、メールサーバは MX レコードとして登録されている。
vwnet.jp ドメインの MX レコードを調べるには、nslookup -q=mx vwnet.jp
とするれば MX レコードを検索することができるのだ。これで目的のメールサーバの IP アドレスが判明するのでメールを相手に送ることができる。
DNSのリソースレコードはMX以外にも数多く存在しており、nslookupやdigでリソースレコードを指定せずに問い合わせをするとA(AAAA)リソースレコードが指定された動作をする。
| DNSリソースレコード | 情報 |
| A | ホストのIPアドレス(IPv4) |
| AAAA | ホストのIPアドレス(IPv6) |
| CNAME | 別名 |
| MX | メールサーバ |
| NS | DNSサーバ |
| PTR | 逆引き情報 |
| SOA | ゾーン情報 |
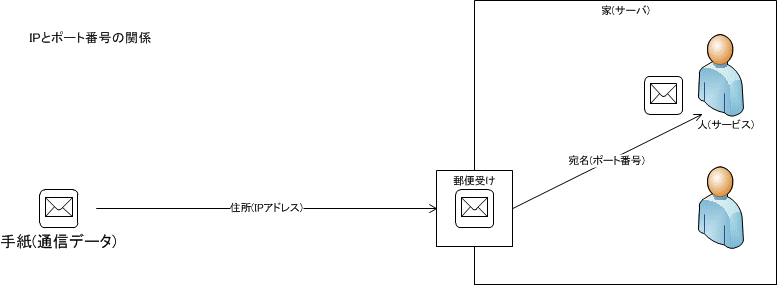
IP アドレスは、相手が住む家のポストまで郵便物を届ける「住所」と言える。家に複数の人が住んでいれば、目的の人に手紙を渡すために「宛先」が必要だ。
サーバの中も Web サーバやメールサーバ、あるいは OS そのものサービスなど複数のサービスが稼働しており、サーバに通信が届いたとしても、目的のサービスに通信が届けられない限り処理をすることができない。
この宛名に相当するのが「ポート番号」だ。ポート番号は http であれば80番、telnet であれば23番と決まっている。
ポート番号は大きく3つに分類されており、0-1023が「well-known ports」、1024-49151が「Registered Ports」、49152-65535が「Dynamic and/or Private Ports」と呼ばれている。
宛先はポートは決められたポートを使用するが、送信元のポート番号は、1024より大きなポート番号をランダムに割り当て送信され、送信元のプログラムは送信元のポート番号で返事が来るのを待ち受けている。IP通信の復路では、送信元のIPアドレスと、送信元のポート番号にしてサーバから送信され、クライアント PC のところまで送り届けられ、待ち受けているプログラムにデータが引き渡されるのだ。
 |
| ポート番号 | サービス | 説明 |
| 20 | ftp-data | File Transfer [Default Data] |
| 21 | ftp | File Transfer [Control] |
| 23 | telnet | Telnet |
| 25 | smtp | Simple Mail Transfer |
| 53 | domain | Domain Name Server |
| 80 | http | World Wide Web HTTP |
| 110 | pop3 | Post Office Protocol - Version 3 |
| 123 | ntp | Network Time Protocol |
| 143 | imap | Internet Message Access Protocol |
| 443 | https | http protocol over TLS/SSL |
| 587 | submission | Submission |
IP 通信では、1500オクテット(1オクテット=8ビット)の細切れにしたデータで通信をしており、細切れのデータを「パケット」と呼ばれている。
ネットワークは細切れのデータで通信するようになって大きく進化したのだ。
パケットが存在する以前の通信は、回線を占有した通信しかできなかった。今では信じられないかもしれないが、1台のコンピュータに対して100台の端末を接続する時には、物的に100本のケーブルを使っていたのである。広域通信をする場合も、1回線では1通信しかできず、専用の回線を何本も敷設しなくてはならなかった。
今では様変わりしつつあるが、その面影を残しているのが電話だ。電話は回線を占有する代表的な通信で誰かが電話機を使って通話をしていると、その電話回線は通話中になっていしまう。
つい最近まで、電話機に接続されている電話回線をたどっていくと、そのままの銅線が電話局の交換機に収容されており、交換機と交換機の間は膨大な数の回線で接続されていた。
受話器を持ち上げて電話番号をダイヤルすると、電話機に接続されている交換機は相手の電話が接続されている交換機との回線を選択し、通話中はこの回線を占有する。
電話交換機が機械化される以前の電話機には電話番号を入力するダイヤルは付いておらず、受話器を上げると電話局の交換手が出て、接続先を告げると電話機の回線を相手局との回線にジャックに刺して、相手局の交換手が電話機の回線ジャックに刺して回線を接続していたのだ。電話交換機は、このジャックを刺す動作を機械化したものだ。
回線占有通信では、膨大な数の通信回線が消費されてしまう。例えばインターネットを回線占有型の通信で作ろうとすると、メールサーバ接続用回線、Google 用回線、楽天用回線と言った具合に、接続するサーバごとに専用の回線を自宅に引き込む必要がある。更には回線占有なので、複数のPCで同時に Google にアクセスするのであれば、同時接続分の回線が必要だ。物理的に収容が難しくなるだけではなく、回線費用も非現実的な費用を支払う必要が出てくるのは容易に想像ができる。
 |
回線占有通信は効率が悪いので、1本の回線で複数の通信を共有させる方法として生まれたのがパケット通信だ。
パケット通信では、元のデータを分割して、各々の分割データに宛先を書いた荷札を取り付けて送信をし、受信側ではバラバラになって送られてきたパケットから荷札を取り外し元のデータへ組立てる。
パケット単位で宛先情報を持っているので1本の回線で複数のコンピュータ同士の通信を共有することが可能になった。
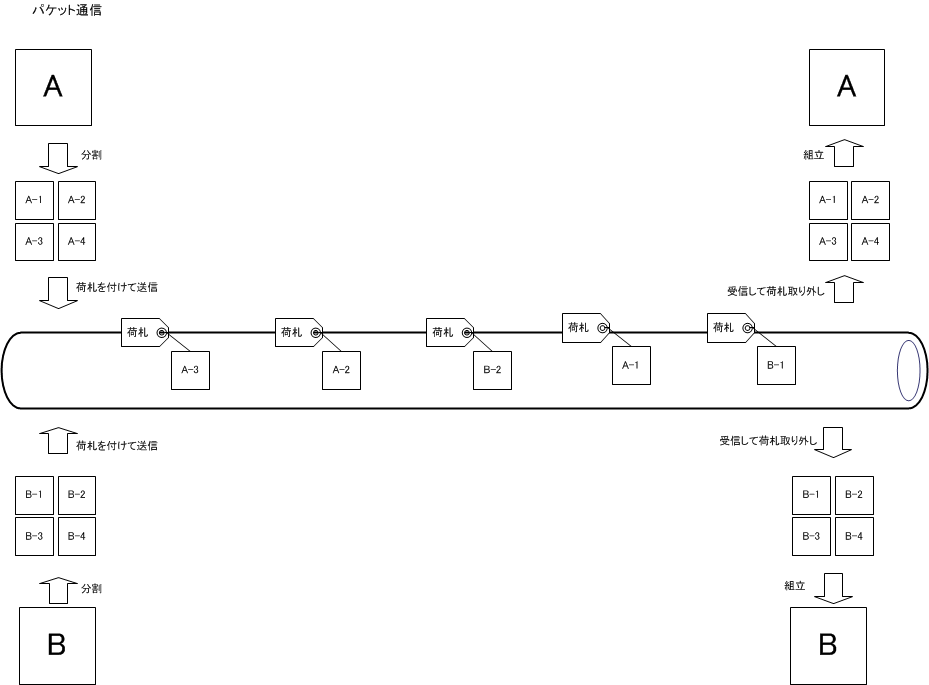 |
IP の中継装置であるルータもパケット単位で中継しているのだが、何かの間違いでパケットが1つ届かない事も発生する。荷札には組立順番も書いてあるので、足りないパケットを送信元に対して再送要求すればデータの欠損が生じない通信が実現できる。このデータを確実に送信するのを実現しているのが TCP だ。
TCP は、データを確実に送り届けるために必要な情報が数多く必要な分重装備なプロトコルになっている。
ところが、通信によっては、確実にデータを届けるより即時性が必要な事もある。例えばインターネット電話やネット動画では、データが欠落した場合の再送をすると、再送のたびに遅延が蓄積され使い物にならなくなってしまう。このような場合は、データ欠落を無視してでも遅延を極力なさなくてはならないが、TCP を使うと通信プロトコルレベルで再送が起きてしまうので都合が悪い。このような即時性が求めらる場合は UDP が使用される。UDP は再送機能を持っていないので、プロトコル自身も軽装備で即時性が求められる通信にはもってこいのプロトコルとなっている。
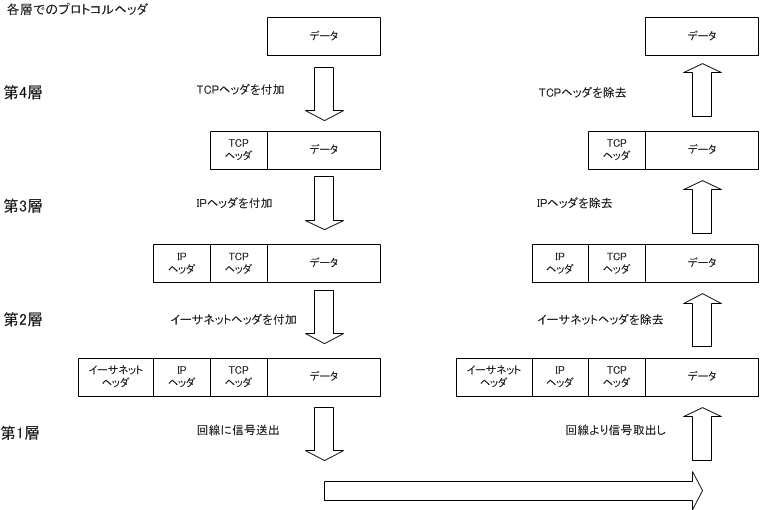
「TCP/IP」は1つのプロトコルのように思われている事が多いが、TCP と IP の2つのプロトコルを言っている。
パケットに取り付けられた荷札の事を「プロトコルヘッダ」と呼んでおり、IP と TCP はそれぞれのプロトコルヘッダを持っている。
プロトコルヘッダも出てきたところで、情報処理試験でもおなじみの「OSI 7階層」について説明しよう。
OSI 参照モデルでは、通信を7階層に分けて考えている。今まで解説してきたIPは第3層(L3)、TCP は L4 に位置している。
| 第7層(L7) | アプリケーション層 | 利用者にmailなどのサービスを提供 | 上位層 |
| 第6層(L6) | プレゼンテーション層 | データを利用者に理解出来る用に変換 | |
| データを通信に適した形に変換 | |||
| 第5層(L5) | セッション層 | サービスレベルのコンピュータ間コネクション確立/開放 | |
| 第4層(L4) | トランスポート層 | データを相手に確実に届ける(TCP/UDP) | 下位層 |
| 第3層(L3) | ネットワーク層 | アドレスの管理と経路の選択(IP) | |
| 第2層(L2) | データリンク層 | 物理的な通信路の確立(イーサネット) | |
| 第1層(L1) | 物理層 | コネクタ形状や電気特性変換 |
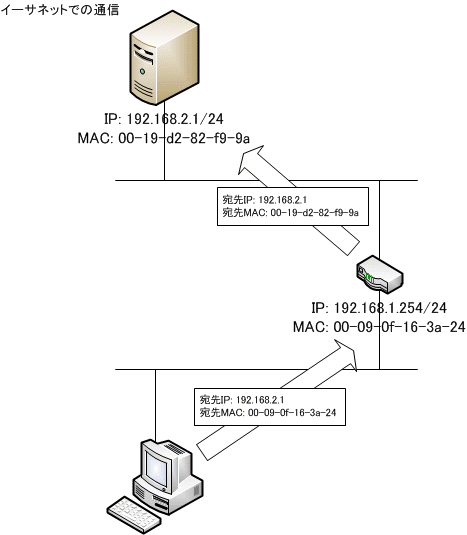
下位層を良く見てみると、物理的なケーブルや電気信号であるL1の前にL2のイーサネットプロトコルが入っているのにお気づきであろうか?
IP は地球の裏側までの通信を実現する広域プロトコルであるが、LAN 上の通信はL2のイーサネットで通信をしている。L2のイーサネットでは、LAN カードや LAN ポートが持っている物理アドレス(MAC アドレス)を使って通信している。LAN 内が MAC アドレスで通信しているので、インターネットの先にあるサーバのIPアドレスを宛先にセットして、ルータの MAC アドレス宛てに送信すると、ルータは自分が持っている IP アドレス以外のパケットを受信して、目的のコンピュータへの中継ができる。
 |
OSI 参照モデルでは、同一層間の通信を「プロトコル」と呼び、上下階層との通信を「インターフェイス」と呼んでいる。上位層に位置している L5-L7 は通信と言うよりサービスの実装に近いので、各層のプロトコルヘッダを持っていない事も多いが、通信そのものともいえる L2-L4 の下位層では各層のプロトコルヘッダを持っており、各層でプロトコルヘッダに基づいた処理をした後にプロトコルヘッダの取り付けと取り外しをしている。
各層の視点では、自分が処理するプロトコルヘッダより後ろは上位層に引き渡すデータと言う事になる。
 |
L5 から L1 に向かって降りて行く際は、下位に位置しているプロトコルが決まっているのであまり問題にはならないが、L1 から L5 に向かって登って良く時は、複数の相手が存在しているので、上位に何が位置しているのか明示的に指定しないと相手がわからない。ポート番号も L4 から L5 に引き渡す際に上位層を指定する際に必要なインターフェイスだ。
L2 のイーサネットから上位層を見ると、IP だけでも IPv4 と IPv6 が存在しているし、IP 以外のプロトコルもイーサネットの上位に位置することができるようになっている。このため、イーサネットヘッダでは、MAC アドレスと上位にプロトコルを識別する「EtherType」が入っている。
| EtherType(16進) | プロトコル |
| 0800 | Internet IP (IPv4) |
| 86DD | IPv6 |
| 8863 | PPPoE Discovery Stage |
| 8864 | PPPoE Session Stage |
同様にIPから上位を見ると、先に解説した TCP と UDP があるし、ICMP 等のプロトコルも IP 上で使われているので、 IP ヘッダには IP アドレスの他に上位プロトコルを指定する「プロトコル番号」もセットされる。
| プロトコル番号 | キーワード | プロトコル |
| 1 | ICMP | Internet Control Message |
| 6 | TCP | Transmission Control |
| 17 | UDP | User Datagram |
| 58 | IPv6-ICMP | ICMP for IPv6 |

OSI 7階層のさらに上位に位置している「人」がメールを使って要件を伝える様子を OSI 7階層イメージで表現すると、L7 では入力された内容を正しく表示するユーザーインターフェイス受け持ち、L6 では UTF-8 等の文字コードの違いを吸収し、L5 でメールサーバとのやり取りをし、L4 でパケットの分解/組立とデータ保障をし、L3 ではルーティングを、L2 ではLAN内の通信、L1 で電気信号で通信をしている。メールの送受信は L7-L1 を上ったり下ったりしてメールサーバとメールクライアント間の通信をしているのだ。
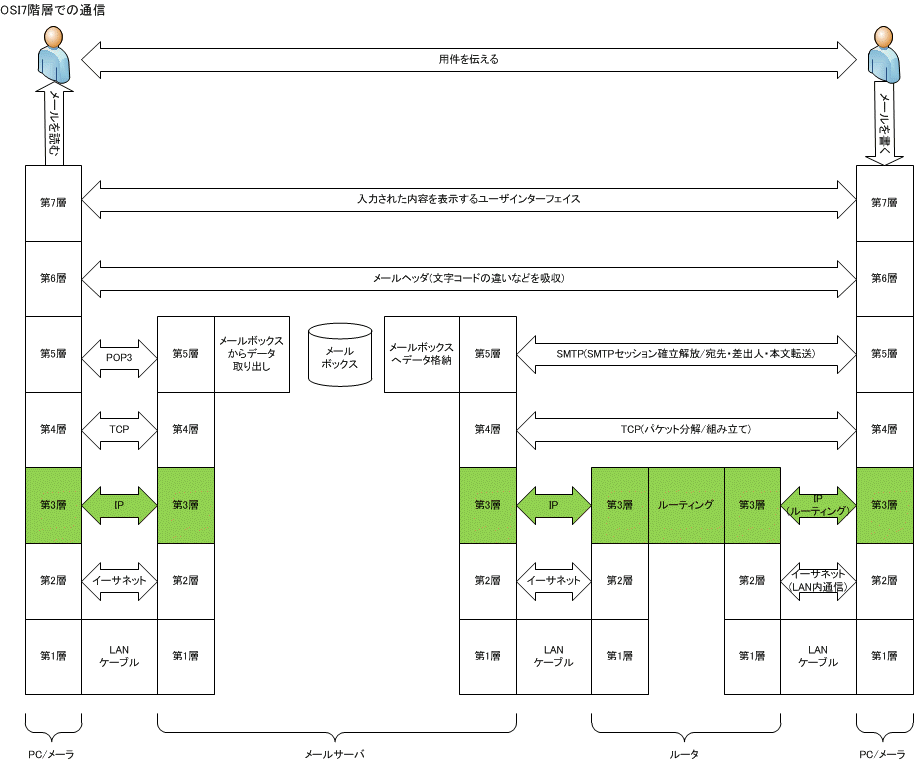 |
IP ヘッダには、パケットの寿命がセットされている。これはパケットが目的地にたどり着くことが出来きず永遠にIP網をさまよい続けるの防止するためのものだ。この寿命が尽きたり、誤ったIPアドレス宛てで目的地そのものが存在しない場合に送信元のコンピュータに不達通知をするのが「ICMP」だ。
ICMP は TCP や UDP のようにデータを運ぶものではないが、不達とかネットワークが混雑しているとかの通信コントロールに必要な情報を伝達する裏方を担っている必要不可欠なプロトコルだ。
全てのクライアント PC に IP を個別に設定するのは骨が折れるので、DHCP を使って IP アドレスを自動構成するのが一般的だ。しかし、サーバには IP を個別に設定するのが普通だ。これは何故であろうか。
DHCP が割り当てる IP アドレスは、DHCP がプールしているIPアドレスの中から空いているIPアドレスを貸し出している。貸し出していると言う事は、返却期限も設定されており、貸出期間が切れた後に同じIPアドレスが割り当てられるか否かはDHCPの設定次第だ。つまり、同じ IP アドレスを使い続ける事が保障されていないのが DHCP が貸し出す IP アドレスの特徴である。
クライアント PC の場合はこの仕様でも構わないが、サーバの IP アドレスがコロコロ変わるのは何かと都合が悪いのでサーバは固定 IP アドレス設定するのが一般的なのである。
IP アドレスには特殊な意味を持つIPアドレスがいくつかあるので、その中で代表的なアドレスを紹介しよう。
| IPアドレス | 用途 | 備考 |
| 0.0.0.0 | 不定アドレス | 全てのIPアドレスを表現する |
| 127.0.0.1 | ループバックアドレス | 自分自身を指し示すIPアドレス(定義は127.0.0.0/8) |
|
10.0.0.0/8 172.16.0.0/12 192.168.0.0/16 |
プライベートアドレス | LAN等インターネットから隔離されたネットワーク上で自由に使用できるIPアドレス |
| 169.254.0.0/16 | リンクローカルアドレス | セグメント内に閉じた通信で使用できるアドレス(DHCPが存在しない場合に自動構成される) |
| 224.0.0.0/4 | マルチキャストアドレス |
ループバックアドレスは、通信テストや複数のサーバサービスが1台のコンピュータ格納され、サービス間で通信する際に良く使われる。
IP アドレスの重複は許されないが、インターネット上で使用しているグローバルアドレスをLANで使用している全てのPCに割り当てると、32ビットのIPアドレスがあっという間に足りなくなってしまう。この問題を解決するのがプライベートアドレスだ。
ライベートアドレスは、インターネットに流さないことを前提に LAN の中だけで自由に使用できる IP アドレスブロックである。
リンクローカルアドレスは、DHCP が存在していないネットワークで使用することが想定されている IP アドレスブロックだ。Windows PC で DHCP が存在しないネットワークではこのアドレスが構成される。実際のところ、この体系の IP アドレスが構成されていたら、DHCP が機能していないと判断する程度にしか使い道がない。
マルチキャストは、同時に複数の PC に対して同じ内容を送信する放送のようなサービスをする際に使われるアドレスブロックだ。
LAN では通常プライベートアドレスを使用するが、LAN からのインターネットアクセス日常的に使用されている。
ところが、プライベートアドレスはインターネット上での使用を認められていないのでそのままではインターネットにアクセスすることが不可能だ。この問題を解決するのが NAT/NAPT と呼ばれるアドレス変換技術だ。言うならば内線番号と外線番号のような関係だ。
IP 本来の思想は完全透過通信なので、アドレス変換をして透過性を捻じ曲げだ NAT/NAPT はグローバル IP アドレスの不足を解決するために必要悪として生まれてきたといえる。
ローカルIPアドレスとグローバル IP アドレスを1:1に単純変換しているのが NAT だ。例えばインターネット上には 211.121.188.192 のグローバル IP アドレスでサーバを構築し、実際のサーバでは10.0.0.1を使って、211.121.188.192と10.0.0.1を変換すると言った使い方だ。
仕組みは単純だが、所有しているグローバル IP アドレスの数しかインターネット接続できない。
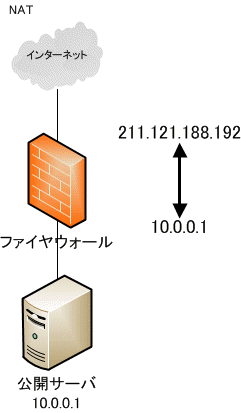 |
多くのクライアント PC からインターネットへアクセスするには、1対1のアドレス変換である NAT は不向きだ。これを解決するのがポート番号とセットで1対多のアドレス変換をする NAPT だ。
NAPT は送信元 IP アドレスと送信元ポート番号のセットで管理し、この単位にグローバル IP アドレスと送信元ポート番号を割り当ててインターネットにパケットを送出する。
戻ってきたパケットには NAPT 装置が割り当てたグローバル IP アドレスとポート番号がセットされているので、元の IP アドレスとポート番号に変換して LAN 側に送り出す。
こうすると、1つのグローバル IP アドレスを使って複数の PC をインターネット接続させる事ができる。
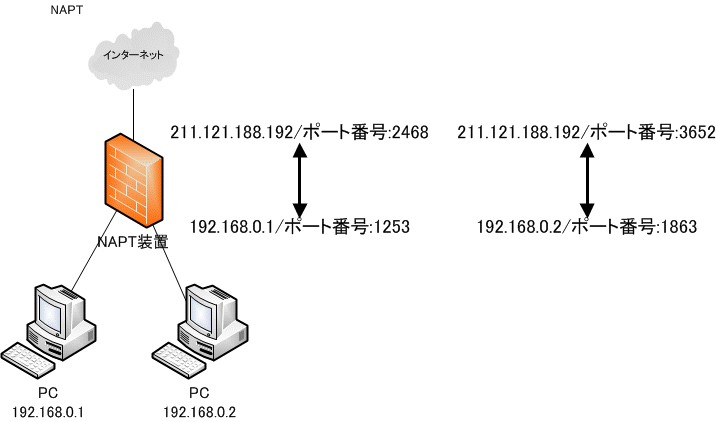 |
IPv4 は軍事研究から生まれた技術で、今日のように世界レベルで普及することが想定されていなかった。このため、インターネット上で使用するグローバル IPv4 アドレスの絶対数が足りないという問題を抱えている。
CIDR や NAPT で延命措置を施してきたが、いよいよ限界に達し2011年にはグローバル IPv4 アドレスの在庫がなくなってしまう見込みだ。これが世に言う「IPv4アドレス枯渇問題」である。
IPv4 アドレスの在庫がなくなったからと言って、いきなりインターネットが停止するわけではないが、新しい IPv4 アドレスが発行できなくなってしまうのでインターネットの拡張が難しくなってしまう。
従来型の Web コンテンツだけではなく、モバイルコンテンツやクラウドコンピューティングの増加だけではなく、TV やハードディスクレコーダー、ゲーム機を筆頭にした情報家電にも IP が使われてので、IP アドレスの消費は増える一方である。この加速に水を差すのが IPv4 アドレス枯渇問題なのだ。
IPv4 アドレス枯渇後は、プロバイダレベルの NAPT(LSN と呼ばれている)や使用していない IPv4 アドレスの回収でしばらくは漕いで行くことになるが、これも焼け石に水でそう遠くない将来に行き詰まることになる。
インターネットの進化を止めないために IPv4 アドレス枯渇問題を根本から解決するのがIPv6である。
IPv4 アドレスは32ビットのアドレス空間を使用しているのに対して、IPv6 は128ビットのアドレス空間を使用する。
仮に地球上の人口を100億人だとすると、IPv4 の場合は一人当たり0.4個の IP アドレスしか割り当てることができないが、IPv6 では3.4×10の28乗といとんでもない数字になる。いくら多くのデジタルデバイスを持っていると言っても、この数を所持することは不可能だ。
IPv6 は、まさに無尽蔵とも言えるアドレス数を持っている。
ただし、IPv6 は IPv4 と互換性が無いため、IPv6 機器と IPv4 機器は通信する事ができない。このため、インターネットが IPv6 化してくると、企業や家庭でも遅かれ早かれ IPv6 を日常的に使わざるを得なくなる。
IPv6 と IPv4 は互換性こそ無いが、IPv6 は IPv4 から進化させたものなので、考え方が同じ所もある。
IPv4 ではネットワークIDとホストIDを区別するためにサブネットマスクを使っていたが、IPv6 もこの考え方は同じだ。IPv4 の場合はビット単位でサブネットマスクを変動させていたが、IPv6 では1セグメントに割り当てるサブネットマスク(IPv6 でプレフィックスと呼ぶ)は64ビットが一般的である。
一番違う点は、IPv4 は1ノード(IP アドレスを持つ機器)は1つの IP アドレスを使うのが前提なのに対して、IPv6 は1ノードは「グローバル」「サイトローカル」「リンクローカル」のように複数の IP アドレス持つことが前提になっている。
グローバル IPv6 アドレスは、インターネット上でユニークな IPv6 アドレスだ。IPv4で はプライベートアドレスを NAT/NAPT で変換していたが、IPv6 では本来の思想に立ち戻るためにアドレス変換をしないのが原則だ。このため、インターネット通信するノードはグローバル IPv6 アドレスを持つことになる。
ローカル IPv6 アドレスは、IPv4 で言う所のプライベートアドレスだ。グローバル IPv6 を LAN 上でも割り当てているので、インターネットプロバイダ(ISP)契約を変更した時に IPv6 アドレスをリナンバーする事になるが、グローバル IPv6 アドレスだけしか持っていない、ISP 切り替え時に一斉にリナンバーしなくてはならず、移行が困難になる。このため、組織内(サイト)で恒久的に使うローカル IPv6 アドレスを定めて、組織内ではローカルアドレスで通信をしておいた方が何かと都合がよい。
IPv6 ノードにはグローバル IPv6 アドレスとローカル IPv6 アドレスの2つを持たせるのが常套手段だ。
IPv6 の面白い点は「リンクローカル IPv6 アドレス」を持っている点だ。IPv4にも169.254.0.0/16のリンクローカルアドレスは定義されているが実質使い物になっていない。これは IPv4 が1ノード1アドレスが前提になっているせいだ。
IPv6 では1ノード複数アドレスなので、IPv6ノ ードにはリンクローカルアドレスを必ず持たせることができ、同じネットワークID(IPv6 ではプレフィックス)の同一セグメント(IPv6 ではリンク)内ではリンクローカルアドレスで通信することができ、IPv4 では使い物にならなかったリンクローカルアドレスが IPv6 では実通信に使われている。
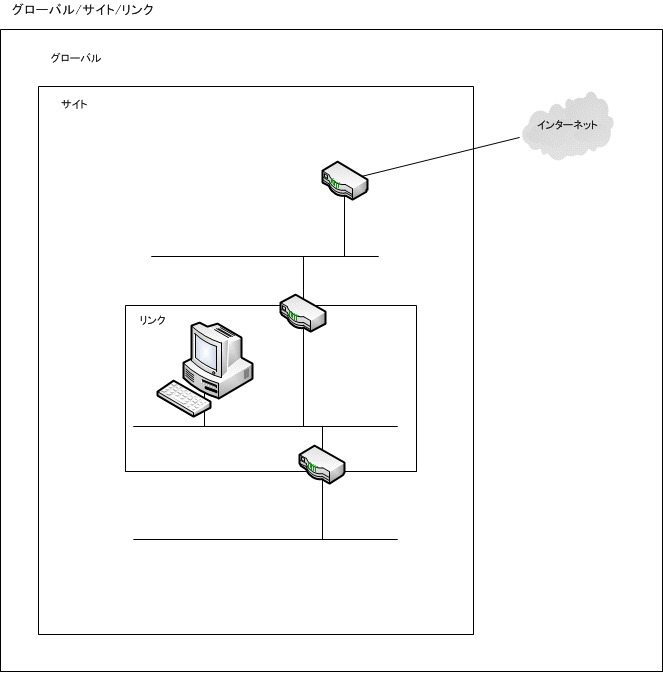 |
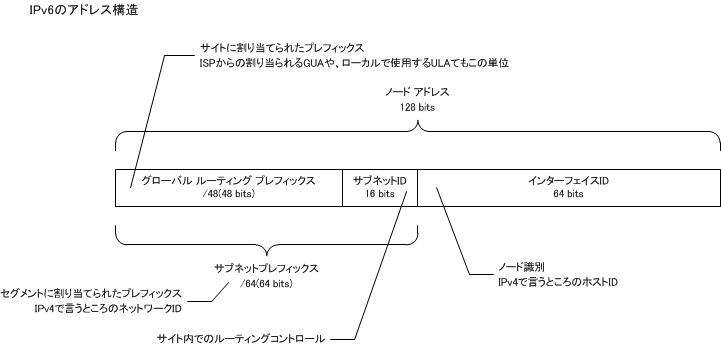
IPv6 アドレスの構造は、前半分64ビットのサブネットプレフィックスと後半64ビットのインターフェイス ID に分かれている。IPv4 で言うところのネットワークIDとホスト ID と同様だ。
サブネットプレフィックスのうち、前48ビットが組織内で使用するサイトプレフィックスとなり、グローバル IPv6 アドレスを取得すると ISP からこのサイズのプレフィックスが配給される。サイトローカルの場合もサイト単位に48ビットプレフィックスを定める事になる。残り16ピットでサイト内のルーティングをする使用する。
 |
IPv6 も IPv4 のように IP アドレスを自動構成することができるが、IPv6 ではサーバであっても自動構成 IPv6 アドレスで運用することが可能になっている。
IPv4 の DHCP では IP アドレスを貸し出す動作しかできないが、IPv6 の DHCP では IPv4 と同様に IPv6 アドレスを貸し出すステートフルと、IPv6 アドレスを貸し出すのではなく IPv6 アドレスを構成するのに必要な情報のみを提供するステートレスの2種類の動作が選択できる。
ステートレスモードでは IPv6 ノードがルータ等の L3 中継機器が提供するプレフィックス情報と DHCP が提供する参照 DNS 等の情報からノード自身が IPv6 アドレスを構成する。このため、MAC アドレスから静的にインターフェイス ID を構成する EUI-64 等を使用すれば、サーバであっても個別に IPv6 アドレスを設定しなくても自動構成で静的 IPv6 アドレスが使用できるようになる。
IPv4 では、32ビットのアドレスを192.168.0.1のように1オクテット(1オクテット=8ビット)ずつ4つに分解した10進数で表現しているが、IPv6 では128ビットのアドレスを2001:db8:7ae3:0:203d:d325:9e45:461dのようにを2オクテットずつ8つに分解した16進数で表現している。
128ビットをそのまま表現すると、16進数でも長くなるので「連続した0000を1ヶ所だけ「::」と省略可」と「先頭の0は省略可」の短縮ルールを適用することができる
このルールを適用すると「2001:0db8:0000:0000:0000:0001:0002:0003」は「2001:db8::1:2:3」と短縮表現することが可能だ。
IPv6 のプレフィックスは、IPv4 の CIDR と同様に「2001:db8:7ae3::/48」のように表現する。
余談ではあるが、RFC 5952 IPv6 Text Representation で IPv6 のアドレス表記が厳密に定められている。以下、JPNIC が公開している「IPv6アドレスの推奨表記、RFC5952ができるまでの道のり [前編]」より厳密に定められた表記ルールを抜粋しておこう。
■IPv6アドレスの推奨テキスト表記
IPv6アドレスのテキスト表記を統一することにより、前述した問題の発生を
低減することが期待できます。
以下に、RFC5952で仕様化された推奨テキスト表記のルールを示します。
(1) 16-Bit Field 内の先頭の"0"は省略すること。
※ "0000"の場合は、"0"にします。
例.2001:0db8::0001 → NG
2001:db8::1 → OK
(2) "::"を使用して可能な限り省略すること。
例.2001:db8:0:0:0:0:2:1 → NG
2001:db8::0:2:1 → NG
2001:db8::2:1 → OK
例.2001:db8:1:1:1::0 → NG
2001:db8:1:1:1:: → OK
(3) 16-Bit 0 Field(="0000")が一つだけの場合、"::"を使用して省略し
てはならない。
例.2001:db8::1:1:1:1:1 → NG
2001:db8:0:1:1:1:1:1 → OK
(4) "::"を使用して省略可能なFieldが複数ある場合、最も多くの16-Bit
0 Fieldが省略できるFieldを省略すること。また、省略できるフィー
ルド数が同じ場合は前方を省略すること。
例.2001:0:0:1:0:0:0:1 の場合、
2001::1:0:0:0:1 → NG
2001:0:0:1::1 → OK
例.2001:db8:0:0:1:0:0:1 の場合、
2001:db8:0:0:1::1 → NG
2001:db8::1:0:0:1 → OK
(5) "a"~"f"は小文字を使用すること。
例.2001:DB8::ABCD:EF12 → NG
2001:db8::abcd:ef12 → OK
IPv6 にも IPv4 と同様に特殊な意味を持つアドレスがいくつかある。
面白いところでは2001:db8::/32のドキュメント用アドレスだ。このアドレスはグローバルアドレスブロック内に位置しているが、書籍や雑誌等のドキュメントで使われるように予約されており、インターネット上で使われることはない。IPv4ではこのアドレスが予約されていなかったのでグローバルアドレスをドキュメントに記述すると、実存するIPアドレスとぶつかってしまう問題があったが、IPv6 ではこの問題が解消されている。
| アドレス | 用途 | 備考 |
| :: | 不定アドレス | 全てのIPアドレスを表現する |
| ::1 | ループバック | 自分自身を指し示すIPアドレス |
| 2000::/3 | グローバル | GUAと呼ばれる |
| 2001:db8::/32 | ドキュメント用 | 書籍/雑誌などのドキュメントで例として使用できる |
| fd00::/8 | ローカル | ULAと呼ばれる。定義はfc00::/7 |
| fe80::/10 | リンクローカル | セグメント(リンク)内だけで使用できる |
| ff00::/8 | マルチキャスト | |
| fec0::/10 | サイトローカル(廃止) | 以前サイト内で使用するローカルアドレスとして定義されていたがULAに席を譲った |
![]()
![]()
Copyright © MURA All rights reserved.